This page shows how I frame questions, clean data, compare models, explain results, and
keep private work private. School projects include more method detail; employer and
client or business-consulting examples use synthetic data or generalized labels.
Featured R/RStudio project
Taxi fare pricing analysis.
A group final project for OPIM 5603 - Statistics in Business Analytics, built in
RStudio and R Markdown. Responsibility was shared across the project; my main
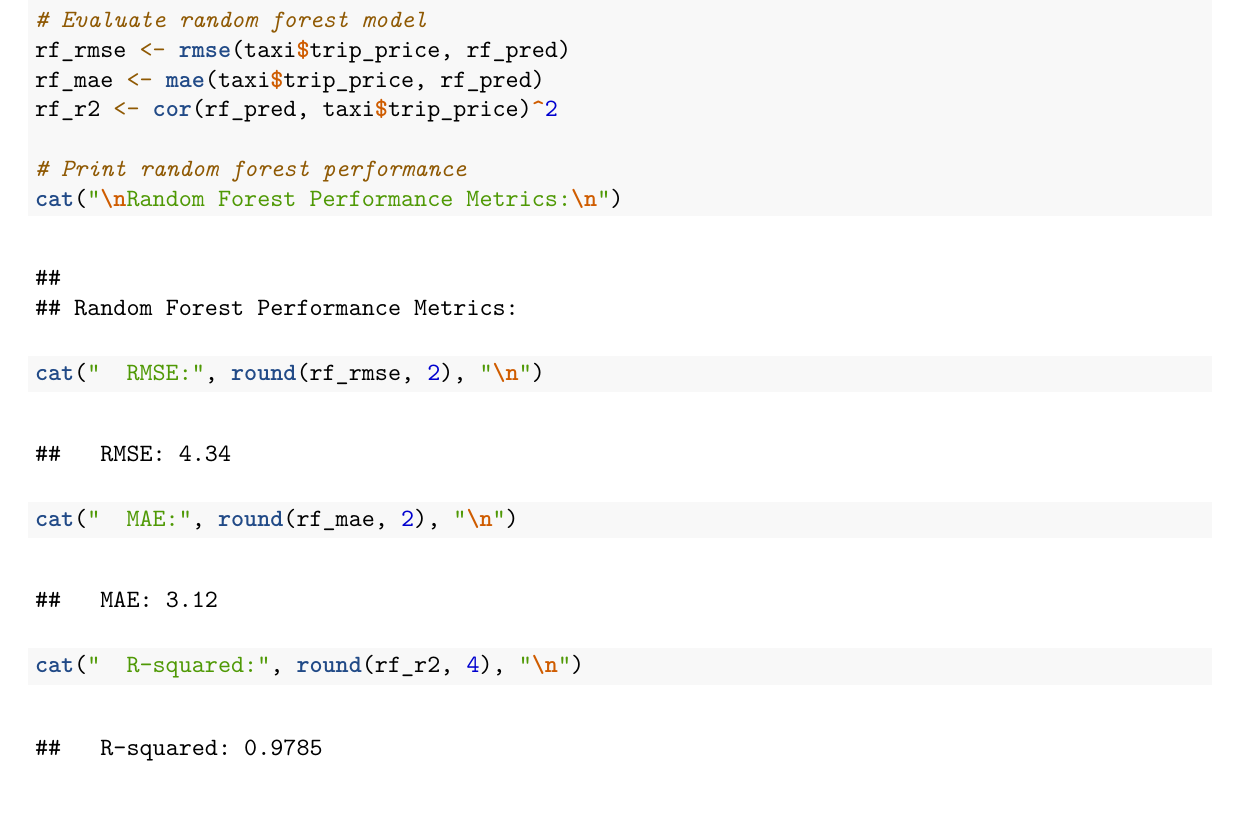
contribution was the random forest model and evaluation section.
What the project did
The project analyzed a 1,000-row taxi pricing dataset with 11 original fields. As a
group, we moved through cleaning, feature engineering, visualization, regression
modeling, random forest comparison, diagnostics, and interpretation. My main section
focused on fitting the random forest model and evaluating RMSE, MAE, and R-squared.
The image shown here is an actual excerpt from that random forest section of the
knitted R Markdown report.
This is group coursework evidence, not a deployed pricing system. The random forest
result is presented as an in-project model comparison, not a production validation
claim.
Distance mattered, but one predictor left too much unexplained.
Multiple regression
15.22
11.91
0.5796
Distance and trip duration were the strongest interpretable drivers.
Random forest
4.34
3.12
0.9785
Nonlinear modeling fit the project dataset much more closely.
Skills shown
Data cleaning, feature engineering, exploratory visualization, regression
interpretation, model comparison, diagnostics, and communicating results in a
reproducible report.
Personal takeaway
Funny enough, working with black-and-white numbers has taught me a lot about creative
thinking. It pushed me to look at business issues less linearly: what is connected,
what is missing, and what question should come next.
Business interpretation
The analysis identified trip distance and duration as the clearest fare drivers, with
traffic, weather, and engineered speed adding useful context around trip efficiency.
AI assistance
AI was useful for syntax support, debugging, and checking explanations. I still treat
the judgment work as human: choosing the question, validating outputs, and explaining
what the results mean.
Additional Python project
Credit default risk modeling.
A group final project for OPIM 5603 - Predictive Modeling, built in Python. Work was
shared across the team; my section focused on the Random Forest classifier and the
model-comparison assessment.
What the project did
The project used a 30,000-row credit-card default dataset to predict whether a client
would default the next month. As a group, we moved through sampling, exploration,
feature preparation, model building, and assessment. My main section fit the Random
Forest model and helped compare test-set ROC AUC across candidate classifiers.
This is group coursework evidence, not a deployed credit-decisioning system. The
metrics are presented as in-project validation results, not a production lending or
underwriting claim.
Strong tree-based comparison model with competitive discrimination.
XGBoost
0.8075
0.6114
0.3557
0.4497
0.7518
Similar ROC AUC to Random Forest with a different precision-recall balance.
Neural Network
0.8180
0.7102
0.2992
0.4210
0.7700
Highest ROC AUC in the project, with lower recall at the default threshold.
Logistic regression with interaction
0.8152
0.7034
0.2841
0.4047
0.7165
Useful interpretable baseline for comparing more flexible classifiers.
Skills shown
Train/validation/test splitting, feature scaling, PCA for correlated billing
variables, classifier fitting, model comparison, ROC AUC interpretation, and clear
communication of validation results.
Business interpretation
The model comparison framed default prediction as a risk-ranking problem, where
accuracy alone is not enough and recall, precision, F1, ROC AUC, and lift all matter.
Contribution boundary
The project was completed by a group. My public claim is limited to the Random Forest
model and the model-comparison assessment shown here.
SQL / ACO operations project
ACO operations reporting database.
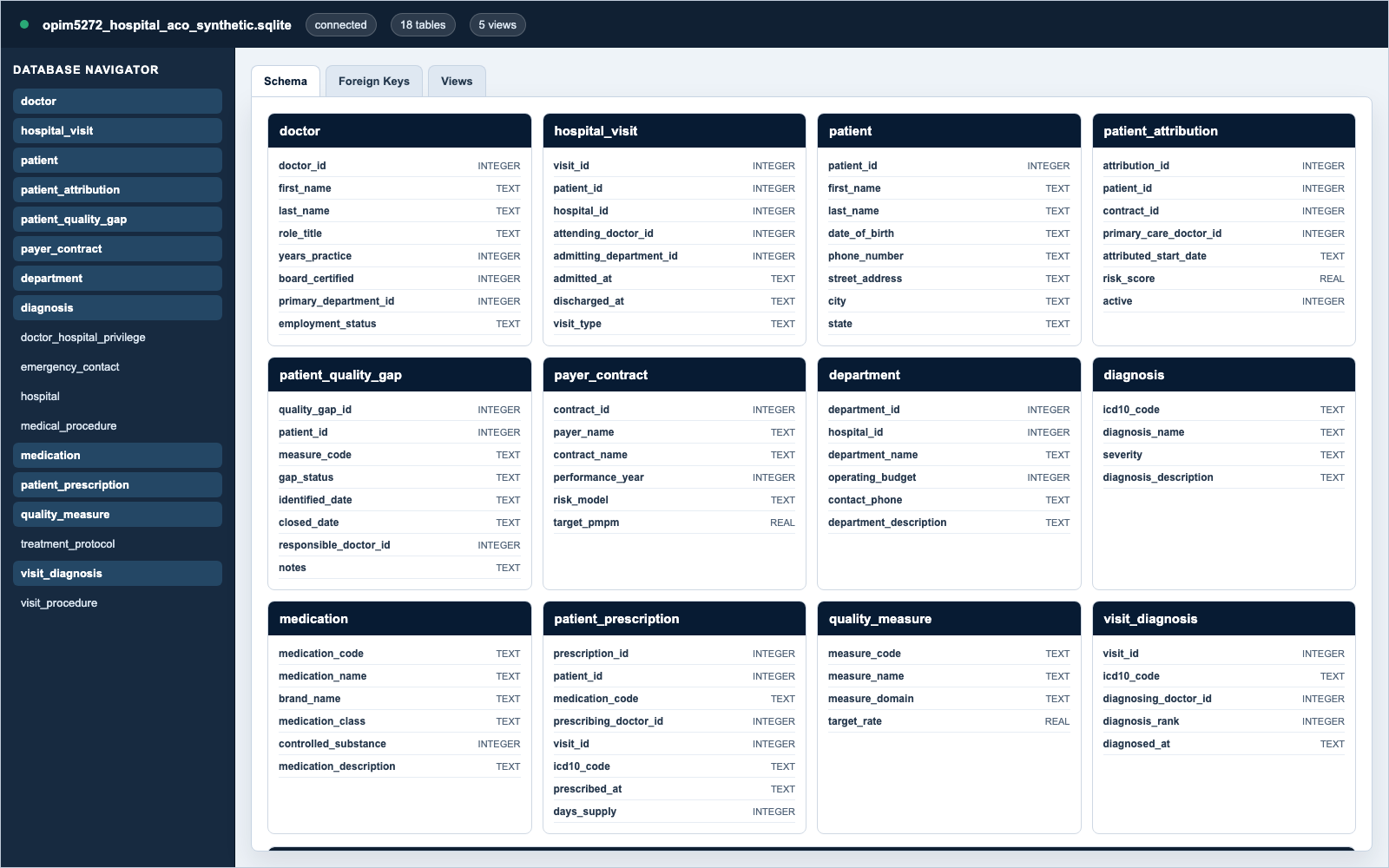
A recreated version of the OPIM 5272 final project concept, rebuilt around the
provider, clinical, member, attribution, and quality data an ACO operations analyst
would need to document, query, and summarize for stakeholders. The original final SQL
was not recovered, so this version uses the recovered Sprint 1 writeup and ERD as
context, then adds cleaner normalization, synthetic source files, loadable SQL, and
reporting views.
What the project models
The original project centered on a New England hospital network with patients,
hospitals, departments, doctors, diagnoses, procedures, medications, emergency
contacts, and administrative reports. I rebuilt that concept as a MariaDB schema and
created a small-ACO source package around it: attributed members, provider
roster, payer contracts, encounters, diagnoses, procedures, prescription history, and
quality gaps. The public display shows the source-to-report workflow: Excel/CSV
intake, normalized SQL tables, reporting views, and stakeholder-ready outputs for
high-risk panels, quality gaps, controlled prescriptions, and department resources.
This is a recreated coursework artifact, not the original submitted final SQL and not
a live hospital or ACO system. All records are synthetic and the claim is limited to
the schema rebuild, data-source design, SQL logic, and portfolio presentation shown
here.
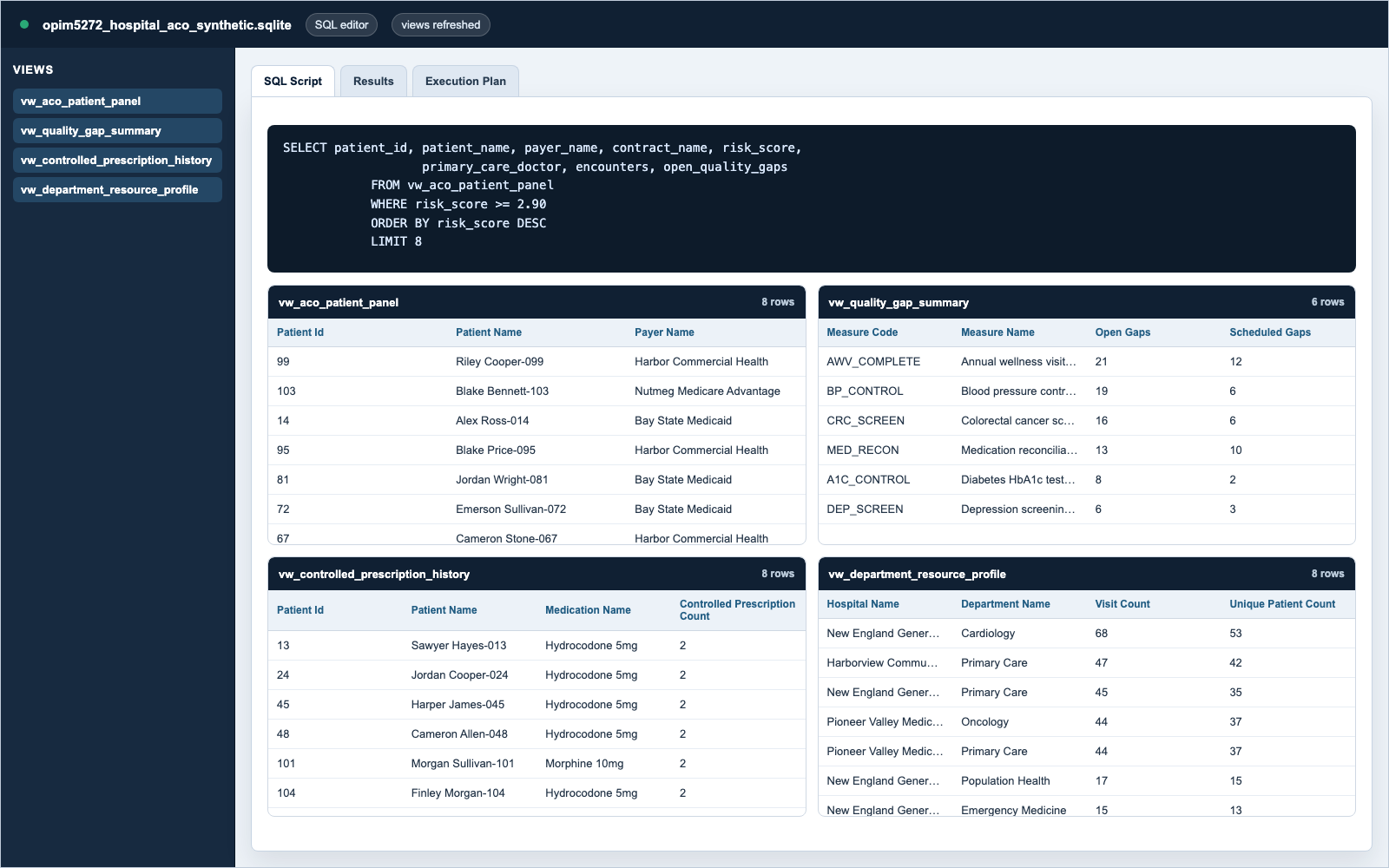
MariaDB reporting view
CREATE VIEW vw_aco_patient_panel AS
SELECT
p.patient_id,
pc.contract_name,
pa.risk_score,
CONCAT_WS(' ', d.first_name, d.last_name) AS primary_care_doctor,
COUNT(DISTINCT hv.visit_id) AS encounters,
SUM(CASE WHEN qg.gap_status IN ('open', 'scheduled') THEN 1 ELSE 0 END)
AS open_quality_gaps
FROM patient p
JOIN patient_attribution pa ON pa.patient_id = p.patient_id AND pa.active = TRUE
JOIN payer_contract pc ON pc.contract_id = pa.contract_id
JOIN doctor d ON d.doctor_id = pa.primary_care_doctor_id
LEFT JOIN hospital_visit hv ON hv.patient_id = p.patient_id
LEFT JOIN patient_quality_gap qg ON qg.patient_id = p.patient_id
GROUP BY p.patient_id, pc.contract_name, pa.risk_score,
d.first_name, d.last_name;
120 attributed patients, 320 encounters, 393 diagnosis rows, 224 prescriptions, and 170 quality-gap records.
Gives enough density to show report behavior while staying small enough for a portfolio reviewer to inspect.
Reporting outputs
High-risk patient panel, quality-gap summary, controlled-prescription history, and department resource profile.
Connects the original hospital-admin report ideas to ACO operations, population-health follow-up, and stakeholder reporting.
Role signal
Mirrors ACO analyst work with provider, clinical, and member data; attribution logic;
quality-gap follow-up; report documentation; and clear summaries for operational
stakeholders.
Rebuild discipline
Normalized relationship tables, consistent naming, explicit primary and foreign keys,
indexes for report paths, check constraints, a deterministic data generator, and a
source-file-to-SQL workflow.
Reports supported
Attributed patient panel, quality-gap summary, controlled prescription history,
doctor activity summary, and department resource profile.
Public boundary
This is a recreated portfolio version from surviving evidence and synthetic data. It is
not represented as a production medical record system, a real ACO extract, or the exact
group submission.
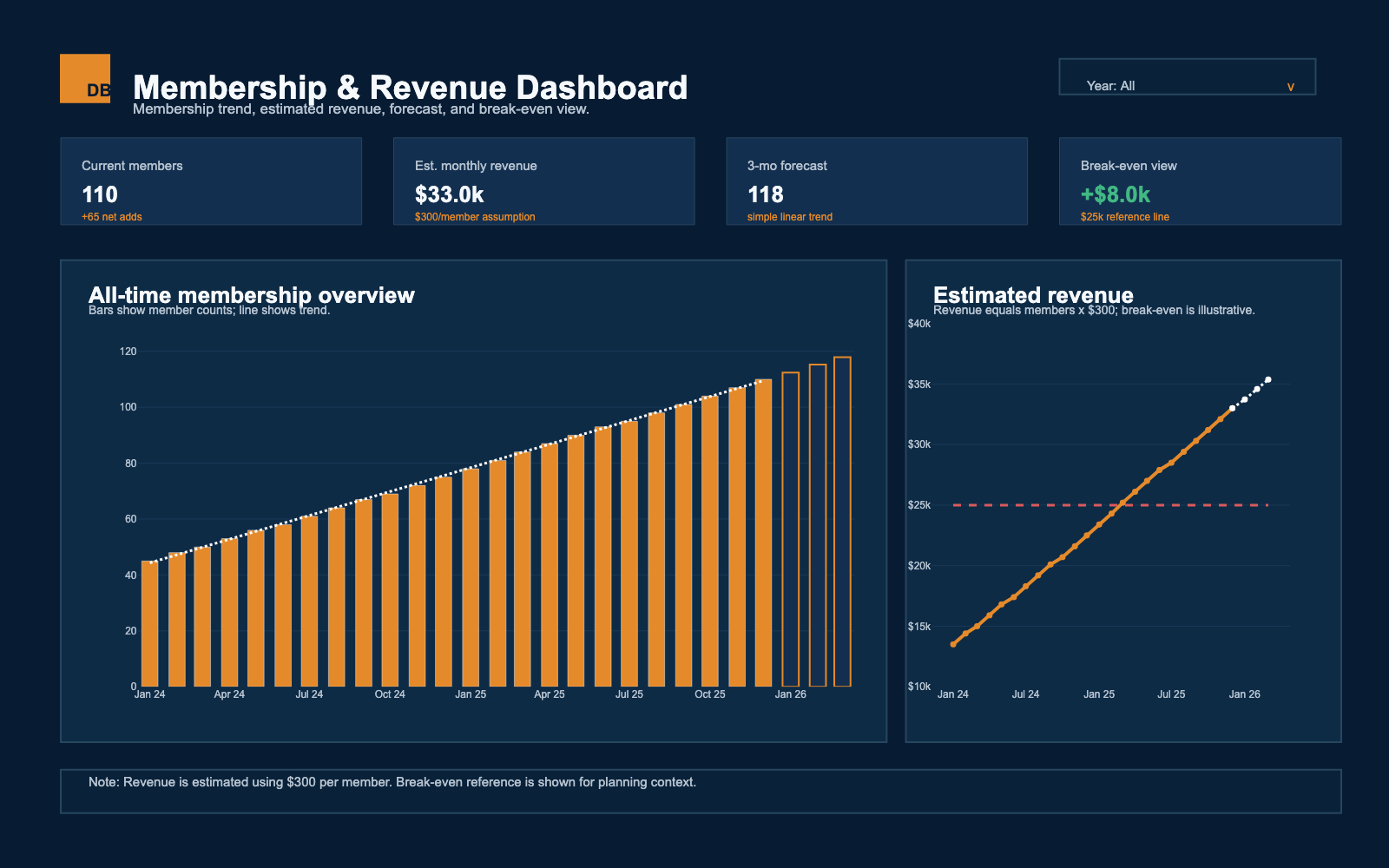
Public dashboard view
A private owner dashboard, shown safely.
The original setup was Square -> Zapier -> Google Sheet -> Python dashboard. Square
activity flowed through Zapier into a private Google Sheet, then a Python Dash app used
Plotly charts, Pandas data prep, and linear regression to turn that spreadsheet activity
into interactive membership and revenue views. I also built an R Shiny version that
read from a private Excel workbook in RStudio, added a year filter, and was designed
to run locally on the owner's computer. A shinyapps.io path was explored, but the
private app is no longer deployed publicly.
Data pipeline
Square transaction activity moved through Zapier into a private Google Sheet, then into the Python dashboard
Local prototype
R Shiny read a private Excel workbook, filtered by year, and plotted monthly membership trend with ggplot2
Business purpose
Help a small-business owner see membership trends, estimated revenue, short-range forecasts, and break-even context
Public visual
The public image uses synthetic data with the same Pandas, regression, Plotly, and Dash-style charting flow, then exports as a static PNG
Privacy boundary
Live sheet access, real member counts, company names, and private operating details are removed
Public display uses synthetic data; no real employer, client, member, or source spreadsheet records are shown.